
Counterpropagation Network (CPN) in Neural Networks: Architecture, Training & Applications
Last Updated: May 6, 2026
The Counterpropagation Network (CPN), introduced by Robert Hecht-Nielsen in 1987, is a hybrid feedforward neural network that combines unsupervised competitive learning with supervised outstar learning. Unlike pure backpropagation networks, CPN trains in two distinct stages and converges much faster, making it useful for data compression, function approximation, and pattern association tasks. This guide covers CPN architecture, the two CPN variants, training algorithms, applications, and how it compares to other neural networks studied in 2026 AI/ML curricula.
What is a Counterpropagation Network?
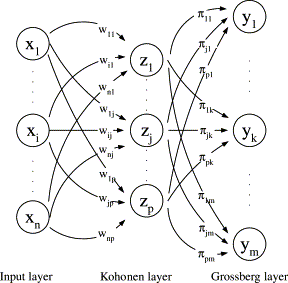
A Counterpropagation Network is a multilayer neural architecture that maps an input vector x to a corresponding output vector y using a hybrid of two classical models, the Kohonen Self-Organising Map (SOM) and the Grossberg Outstar. The Kohonen layer performs unsupervised clustering of input patterns; the Grossberg outstar layer learns to associate each cluster with the desired output.
CPNs are part of the broader instar-outstar family proposed by Stephen Grossberg, structured as three sequential layers:
| Layer | Function | Learning Type |
|---|---|---|
| Input Layer | Receives the input vector x | None (passive) |
| Hidden / Kohonen / Cluster Layer | Clusters similar input patterns via competitive learning | Unsupervised |
| Output / Grossberg / Outstar Layer | Maps each cluster to the desired target output | Supervised |
Two Variants of CPN
1. Full Counterpropagation Network
The full CPN provides a bidirectional mapping. It can produce an output y given an input x, and conversely produce x given y. The network has two pairs of input-output vectors and is symmetric.
Use cases: Data compression where you need to recover an approximate input from a compressed representation, and pattern association where the mapping is bidirectional (e.g., Hindi word ↔ English word).
2. Forward-Only Counterpropagation Network
The forward-only CPN is a simpler version that performs unidirectional mapping (input → output only). It uses fewer weights and is faster to train. This is the more commonly used variant in practical applications.
Use cases: Function approximation, classification, and any application where only forward mapping is needed.
CPN Training Algorithm: Two-Stage Process
Stage 1: Train the Kohonen (Cluster) Layer (Unsupervised)
- Initialise weights between the input layer and the Kohonen layer to small random values.
- Present an input vector x to the network.
- Compute the distance (typically Euclidean) between x and the weight vector of each Kohonen neuron.
- Identify the winner: the Kohonen neuron with the smallest distance (closest weight vector).
- Update the winning neuron’s weights to move closer to x:
wwinner(new) = wwinner(old) + α × [x − wwinner(old)]
where α is the Kohonen learning rate. - Decrease α gradually and repeat until weights converge or a fixed number of epochs is reached.
Stage 2: Train the Grossberg (Outstar) Layer (Supervised)
- Initialise weights between the Kohonen layer and the output layer.
- Present an input-target pair (x, y) to the network.
- Forward propagate x to identify the winning Kohonen neuron (using weights from Stage 1).
- Update the weights from the winning Kohonen neuron to each output neuron:
vi(new) = vi(old) + β × [yi − vi(old)]
where β is the Grossberg learning rate. - Repeat over all training samples until output error is acceptable.
Applications of Counterpropagation Networks
- Data compression: Map high-dimensional input to a low-dimensional cluster representation, then back to the input.
- Function approximation: Approximate non-linear functions where backprop networks would take much longer to converge.
- Pattern association: Map associated patterns, e.g., a Hindi character to the English transliteration, or a face image to a name.
- Statistical analysis: Approximate probability density functions of input data.
- Classification: Classify input vectors into a fixed number of categories based on similarity.
- Control systems: Map sensor readings to control signals in robotics applications.
- Optical character recognition (OCR): Used in early OCR systems for character pattern association.
Advantages of CPN
- Fast training compared to backpropagation networks. CPN converges in fewer epochs because the Kohonen and Grossberg layers train independently.
- Simple implementation, the math is more straightforward than backpropagation’s gradient computation.
- Local learning, only the winning neuron and its outstar weights are updated, reducing computation per step.
- Good generalisation for low- to mid-dimensional problems with clear cluster structure.
- Self-organising, the clustering layer discovers structure in the input automatically.
Disadvantages of CPN
- Number of clusters must be specified in advance. Choosing too few or too many degrades accuracy.
- Sensitive to weight initialisation. Poor initial weights can leave some Kohonen neurons “dead” (never winning).
- Lower accuracy than modern deep networks on complex high-dimensional problems like natural images.
- Not naturally suited for sequence data (CPN is feedforward; for sequences, RNN, LSTM, or Transformer architectures are used).
- Discrete winner-take-all means CPN can be unstable near cluster boundaries.
CPN vs Backpropagation Network
| Feature | CPN | Backpropagation Network (MLP) |
|---|---|---|
| Learning | Hybrid (unsupervised + supervised) | Fully supervised |
| Training time | Fast | Slow (especially deep networks) |
| Generalisation | Good for low-mid dimensional, clusterable data | Excellent for high-dimensional, complex data |
| Mathematical complexity | Simple | Complex (chain rule gradients) |
| Modern relevance (2026) | Mainly academic / specialised use | Foundation of all deep learning |
Where CPN Sits in 2026 Neural Network Curricula
Most B.Tech and M.Tech curricula in India still cover CPN in the Soft Computing or Neural Networks elective, typically in Unit 3 alongside Kohonen SOMs and Adaptive Resonance Theory (ART). It is a useful conceptual stepping stone, students who understand CPN’s two-stage structure grasp deep autoencoders, vector quantization, and clustering layers in modern transformer architectures more easily.
For competitive exams (GATE Computer Science, ISRO scientist recruitment), CPN questions appear in the Artificial Intelligence and Machine Learning sections, especially conceptual questions about Hecht-Nielsen’s contribution and instar-outstar architecture.
Frequently Asked Questions
Who invented the Counterpropagation Network?
Robert Hecht-Nielsen proposed the Counterpropagation Network in 1987 at the IEEE International Conference on Neural Networks. It was conceived as a faster alternative to backpropagation for function approximation tasks.
What are the layers in a Counterpropagation Network?
CPN has three functional layers, but two trainable layers: the Kohonen (clustering) layer that uses unsupervised competitive learning, and the Grossberg (outstar) layer that uses supervised learning to map clusters to target outputs.
What is the difference between Full and Forward-Only CPN?
Full CPN performs bidirectional mapping (x↔y) using two pairs of input-output vectors. Forward-only CPN performs only x→y mapping using fewer weights. Forward-only is more commonly used in practice.
What learning rules does CPN use?
CPN uses the Kohonen learning rule (winner-take-all) for the cluster layer and the Grossberg outstar learning rule for the output layer. Both are local learning rules, only the winning neuron’s weights and its outstar weights are updated each step.
Is CPN still used today?
CPN is rarely used in production deep learning today (transformers and CNNs have superseded it for most tasks), but it remains an important academic concept. Variants of competitive learning persist in vector quantisation, k-means clustering, and the classification heads of modern self-supervised models.
What are the typical applications of CPN in modern projects?
Modern CPN applications include legacy data compression in resource-constrained embedded systems, fast prototyping of pattern-association problems, and educational implementations for teaching the relationship between unsupervised and supervised learning.
Related Topics in Neural Networks
- Biological Neuron vs Artificial Neuron
- Error Back Propagation Algorithm
- Adaline and Madaline Networks
- Artificial Neural Network, Introduction
- Associative Memory in Neural Networks
- ART (Adaptive Resonance Theory)
Conclusion
The Counterpropagation Network bridges the conceptual gap between unsupervised clustering and supervised mapping, training faster than backpropagation while remaining intuitive enough to grasp without heavy calculus. It is a fundamental architecture in any neural networks course and a useful starting point for understanding more sophisticated hybrid learning systems used today. For exam preparation and academic projects, CPN is worth implementing once in your preferred language to internalise how the Kohonen and Grossberg layers cooperate.
Discover more from Our Education | Best Coaching Institutes Colleges Rank
Subscribe to get the latest posts sent to your email.
sir how to study soft computing and how to gain practivcal knowledge in python