
Notes for breadth first search and dept first search
Last Updated: May 23, 2013
BREADTH FIRST SEARCH AND DEPTH FIRST SEARCH
Breadth first search:
It is a simple strategy in which the root node is expanded first then all the successors of the root node is expanded next, then their successors and so on.It is one among the uninformed search also called blind search.
This can be implemented by calling TREE-SEARCH with an empty fringe that is a first in first out (FIFO) queue that is node that are visited first will expand first.

Tree diagram
The sallowestgoal node is not necessarily the optimal one;technically, breadth first is optimal if the path cost is a non-decreasing function of the depth of the node.
The memory requirements are the bigger problem in breadth first search and also the time required. For eg. it takes 31 hrs and terabyte memory to search in node 8. There are other searches which will take less time and memory.
The root of the search tree generates b node at the first level, each of which generates b more nodes, for a total of b2 at the second level.in the worst case ,we would expand all but the last node at level d generating b d+1 –b nodes at level d+1,where d is the depth of the tree. Then the total number of nodes generated is
b+b2 +b3+…..+bd+ (bd+1-b) =O (bd+1)

Time and memory requirements
Every node that is generated must remain in memory, because it is either part of the fringe or is an ancestor of a fringe node.
Depth first search:
This search always expands the deepest node in the current fringe of the search tree. The search proceeds immediately to the deepest level of the search tree, where the nodes have no successors.
This strategy can be implemented by tree search with a last in first out (LIFO) queue, which is nothing but a stack. The implementation of the depth first search with a recursive that calls itself on each of its children in turn.
It has very modest memory requirements. It needs to store only a single path from root to a leaf node, along with the remaining unexpanded sibling nodes for each node on the path.
A variant depth first search called back tracking search uses still less memory. In backtracking only one successor is generated at a time rather than all successors; each partially expanded node remembers with successor to generate next.
For eg branch factor – b, maximum depth – M it requires storage of bM+1, it would require only 118 kilobyte for 10 petabytes at dept d=12. Its a factor of 10 billion times less space.
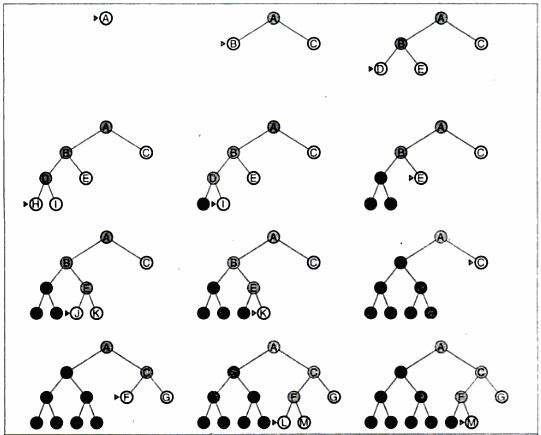
depth first search on a binary tree
The drawback of this search is that it can make a wrong choice and get struck going down a very long path when a different choice would lead to a solution near the root of the search tree.
For more information in
breadth first search https://blog.oureducation.in/depth-first-search/
depth first search https://blog.oureducation.in/breath-first-search/
Discover more from Our Education | Best Coaching Institutes Colleges Rank
Subscribe to get the latest posts sent to your email.
Tell us Your Queries, Suggestions and Feedback
3 Responses to Notes for breadth first search and dept first search
« Placement Criteria for Zensar Technologies Fuzzy Set Theory »
B. Tech
B. Tech
B. Tech