
Sequence Alignment
Last Updated: May 28, 2013
Sequence Alignment:
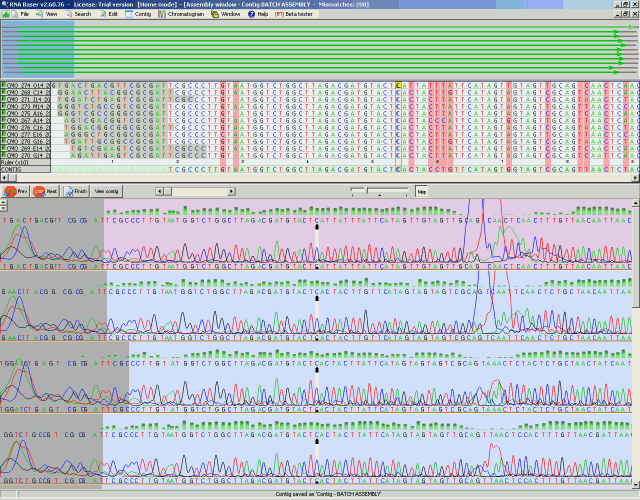
Example of sequence alignment in DNA Baser Sequence Aligner
Sequence alignment is a procedure which may be implicit or explicit conducted in biological study that compares two or more biological sequences (whether DNA, RNA, or protein). This procedure attempts to infer which positions within the sequence are homologous. Homologous refers to that sites those share the evolutionary history that are found to be common.
Optimal Alignment
It is that alignment whose score lies in the neighborhood of the optimal score.
Between the pair of proteins or nucleic acids the optimal alignment does not necessarily reflect the correct biological evolution.
Alignments of those proteins are based on the DNA sequences based on the evolutionary changes. These alignments are different from the alignments that minimizes the edit distance
In many cases the edit distance alignment is a better approximation than the biological one.
Methods:
Methods are presented for representing the alignments whose score is under any given delta from the original score.
The number of alignments is represented using a compact graph, which helps in imposing additional biological constraints and selects one desirable constraint for the large set.
The graphical representations show in a dramatic way, all the possible alignments without the need of enumerate them.
Multiple sequence alignment:
Multiple sequence alignment is a optimization problem that is computationally hard and which involves the considerations of different alignments in order to find an optimal one, when given a measure of goodness of alignments.
The multiple sequence alignment problems use various criteria of optimality that is basically shown in NP-HARD.
DYNAMIC PROGRAMMING
Dynamic programming algorithms are used for the search of optimal alignments. They are constrained to unwieldy space requirements by large number of sequences.
There are several methods devised that helps to reduce the search space for an optimal alignment under a sum of pair measure.
Dynamic programming is widely used to solve the optimization problem of aligning sequences.
The asymptotic complexity of dynamic programming increases exponentially with the dimension.
Discover more from Our Education | Best Coaching Institutes Colleges Rank
Subscribe to get the latest posts sent to your email.
the post above gives the details of how the alignment is compared by using two or more DNA’s by checking its A-G-T-C component arrangement. these are helpful in forensic science as would help to solve the cases easily. Great piece of writing
nice written about sequence alignment is a way of arranging the sequences of DNA, RNA, or protein to identify regions of similarity that may be a consequence of functional, structural, or evolutionary relationships between the sequences.
The post is a short note about different types of alignments and the methods used in it.Going through the article can be helpful !!!
The article comprises about the sequence alignment . For those who are unaware can go through this and can acquire knowledge.