
BPUT SAMPLE PAPER FOR ADAPTIVE SIGNAL PROCESSING
Last Updated: Jun 5, 2013
SAMPLE PAPER FOR ADAPTIVE SIGNAL PROCESSING

ADAPTIVE SIGNAL PROCESSING
FULL MARKS:-70
Q.1 is compulsory and comprising 20 marks(2 marks for each bit)
Q.2 – Q.7 (do any five) are comprising10 marks for each.
1.
(a) Write the normal form of input co-relation matrix.
Ans:- Correlation matrix = R =E [u(n) u^H (n)]
Where, u(n) = [u(n) u(n-1) ……….u(n-m+1)]
And u^H(n) Hermittian Transportation of u(n).
(b) What is the difference between Newton’s method and Steepest Descent method?
Ans:- Newton’s method is a method of gradient search that causes all the component of weight vector to be changed at each step in the search procedure or at each iteration cycle, where as ,
Steepest descent method is a method of gradient search that also causes all component of weight vector to be changed at each or each iteration cycle
(c) What is Pertubation?
Ans:- A dimension measure of the effect of gradient estimate on the adaptive adjustment is called “perturbation” (p).
P= γ / ϵmin =λ Δ^2 / ϵmin
(d) What do you mean by geometric ratio?
Ans:-We know that,
Wk = W* +(1-2μλ)^k (Wo – W*)
Here, 1-2μλ = r
This is known as geometric ratio as it is the ratio of successive terms in the geometric sum.
(e) What do you mean by the learning curve?
Ans:- Learning curve is the plot between the mean square error ϵk and iteration number k.
(f) State the characteristics of ASP.
Ans:- Characteristics of ASP:-
(i) They can automatically adjust or adapt in the face of changing environment.
(ii) They can be trained to perform specific filtering and decision making task.
(iii) To a limited extent they can repair themselves.
(iv) They can usually be described as time varying system with the time varying parameter.
(g) what do you mean by performance penalty?
Ans:- Performance penalty is defined as the increase in γ brought about by misadjusting the weight and not leaving it set at v.
Performance penalty = γ = { [ϵ (v-Δ) + ϵ (v+Δ) ] / 2 } – ϵ (v)
(h) What do you mean by mean square error?
Ans:- Mean square error or ϵ is a quadratic function of the weight vector ‘w’ when the i/p components and desired response are stationary stochastic variable.
So, MSE(Δϵ) = E (ϵk^2] + d^2k + Wk^T RWk – 2 P^T Wk
(i). What do you mean by stochastic process?
Ans:- Stochastic process is a random process which is used to describe the time evaluation of statistical phenomenon. Time evaluation means the stochastic process is a function of time defined some observation interval.
(j) The estimated gradient in LMS algorithm is unbiased one. What would be the effect on convergence, if the estimate is biased one?
Ans:- Convergence is one of the primary function of LMS algorithm i.e., convergence to optimum weight. The estimate gradient is unbiased for this. If it is biased then we can not make LMS algorithm into a true Steepest descent algorithm Here, it may adapt the weight until many steps occurred.
2.
(a) Adaptive signals are non linear. Justify
Ans:- Adaptive signal are non-linear
* Let an i/p signal X1 is applied system will accept it and produce an o/p Y1.
* If another i/p signal X2 is applied, then the adaptive system will accept it and produce an o/p, let Y2.
* Generally, the form or the structure or adjustment of the adaptive system will be difficult for the adaptive system will be difficult for the different inputs.
* If H is adaptive, then Y3 ‡ Y1 + Y2. Hence, adaptive signals are non- linear.
(b) Show that the gradient search algorithm is stable when 1 / λ > μ >0 where λ is eigen value and μ is a parameter which gives stability and rate of convergence.
Ans:- We know that geometric ratio is
1 – 2μλ = r…………(1)
It is geometric ratio of successive terms in the geometric sum →
Wk = (1- 2μλ )^ k Wo + 2μλω* ϵ [runs from n=0 to k-1] (1 – 2μλ)^n
Eqn (1) becomes stable if and only if
[ 1-2μλ ] = [r] < 1This is the stable condition.
It can be written as,
1 / λ > r > 0
Hence is stable when gradient search algorithm is stable when 1/λ > r > 0.
3. Prove that for a real auto correlation matrix R all the eigen values are must be real and eigen vector corresponding to distinct eigen values of R are mutually orthogonal.
Ans:- Let λ1 & λ2 be two distinct eigen values.
RQ1 = λ1 Q1…………….(i)
RQ2 = λ2 Q2……………(ii)
We take transposed and multiply with Q2
Q1^T R^t Q2 = λ1 Q1^T Q2………………(iii)
Again we multiply by Q1^T
Q1^T R Q2 = λ2 Q1^T Q2……………(iv)
R = R^T
By combining eqn (iii) & (iv), we get,
=> λ1 Q1^T Q2 = λ2 Q1^T Q2
=> Q1^T Q2 = 0
Hence, eigen vectors λ1 & λ2 are orthogonal.
4. What do you mean by correlation matrix? Write four properties of correlation matrix.
Ans:- Let m × 1 observation vector i.e. u(n) represents the elements of zero mean type series u(n), u(n-1), …………u(n-m+1).
So, u(n) = [u(n), u(n-1), ………………u(n-m+1)^T m×1……..(i)
Where T= transposition
We can define correlation matrix of stationary discrete time stochastic process represented as this time series as the expectation of the outer product of observation factor u(n) with itself . so, let R denote the maximum correlation matrix.
R= E[u(n). U^H(n)………………(ii)
Where, u^H(n) = Hermitian transpose of u(n)
Property
(i) The correlation matrix of a stationary discrete time stochastic process is Hermitian ; R=R^H
(ii) The correlation matrix of a stationary discrete time stochastic process is Toeplitz.
(iii) The correlation matrix of a discrete time stochastic process is always non-negative definite and almost always positive definite.
(iv) When the elements that constitute the observation vector of a stationary discrete time, stochastic process are rearranged in backward, the effect is equivalent to the transportation of correlation matrix of the process.
5. Show that the estimated gradient of weight vector is unbiased.
Ans:- True gradient = 2RW – 2P
Estimated gradient = -2 ek Xk
To estimate the convergence we have to note that the gradient estimate radially shown to be unbiased, when weight vector is held constant.
The expected value of estimated gradient with Wk held equal to
W = E[-2 ek xk]
= -2E [ek wk]
= -2E[ (dk – yk)xk]
=-2E[ (dk – xk^T wk) xk]
=-2E[dk xk – xk^T wk xk ]
= -2{ E [dk xk] – E [xk^T wk xk]}
= -2{P – E [xk^T xk] wk}
=-2 {P – Rwk}
When wk = w then
Expected value of estimated gradient with wk held equal to w is equal to
= -2 (P – Rw)
= 2 (RW – P)
= 2RW -2P
Hence estimated gradient is unbiased
6. Give a example of performance surface.
Ans:- A simple example of single input adaptive linear combiner with 2 weights
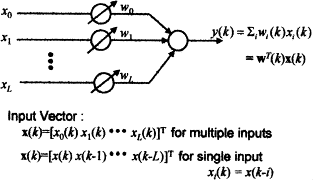
Fig:- Adaptive linear combiner
The input desired signals are sampled sinusoids at the same frequency with N samples per cycle. We assume that N > 2. So, that the i/p samples are not all zero. We are not concerned here with the origin of these signals only with resulting performance surface and its properties.
To obtain the performance fuction, we need the expected signal products. We must change the subscript of x for single i/p case. The expected products may be found for any products of sinusoidal functions by averaging over one or more periods of the product.
Thus E[ xk xk-n ] = 0.5 cos 2πn / N ; n=0,1……….(i)
E[dk xk-n] = -sin 2πn / N, n=0,1…………………….(ii)
We further note that obviously,
E[ xk-1^2] = E[xk^2] ,because the average is over k.
With these results the i/p correlation matrix R and the correlation vector P can be obtained for the two-dimensional single i/p.
7. Short note on Adaptive Noise Cancelling.
Ans:-
→ A signal is transmitted over a channel to a sensor that receives the signal plus an uncorrelated noise no.
→ The combined signal and noise that is s+no is the primary i/p.
→ A second sensor receives a noise n1 which is un-correlated with the signal but correlated in some unknown way noise no.
→ This sensor provides reference i/p to the adaptive noise canceller.
→ The noise n1 is filtered to produce an o/p that is y that is close to the replica of no. The o/p is subtracted from the primary i/p (s+no) to produce the system o/p (s+no-y).
→ In noise cancelling system the replica objective is to produce a system o/p (s+no-y) that is best fit in the least square sense to the signals.
→ The objective is accomplished by feeding the system o/p back to the adaptive filter and adjusting the filter through an adaptive algorithm to minimize the total system o/p power.
→ In an adaptive noise cancelling system, the system o/p serves as the error signal for the adaptive process.
→Minimising o/p power causes the o/p signal to be free from noise.
Advantages
(i) Adaptive capability
(ii) Low o/p noise
(iii) Low signal destruction.
Discover more from Our Education | Best Coaching Institutes Colleges Rank
Subscribe to get the latest posts sent to your email.
« CBSE Class 12 Mathematics Sample Paper: Pattern, Topics & Preparation Tips Data Base Management System Sample Paper »
Tell us Your Queries, Suggestions and Feedback