
A Star Search
Last Updated: May 3, 2013
A Star Search
A-Star (or A*) is a general search algorithm that is extremely competitive with other search algorithms, and yet intuitively easy to understand and simple to implement. Search algorithms are used in a wide variety of contexts, ranging from A.I. planning problems to English sentence parsing. Because of this, an effective search algorithm allows us to solve a large number of problems with greater ease.
What A-Star does is generate and process the successor states in a certain way. Whenever it is looking for the next state to process, A-Star employs a heuristic function to try to pick the best state to process next. If the heuristic function is good, not only will A-Star find a solution quickly, but it can also find the best solution possible.
Here’s a more detailed look at how A-Star operates. The algorithm maintains two sets, the OPEN list and the CLOSED list. The OPEN list keeps track of those nodes that need to be examined, while the CLOSED list keeps track of nodes that have already been examined. Initially, the OPEN list contains just the initial node, and the CLOSED list is empty. Each node n maintains the following:
g(n) = the cost of getting from the initial node to n.
h(n) = the estimate, according to the heuristic function, of the cost of getting from n to the goal node.
f(n) = g(n) + h(n); intuitively, this is the estimate of the best solution that goes through n.
Each node also maintains a pointer to its parent, so that later we can retrieve the best solution found, if one is found.
A Star Search
has a main loop that repeatedly gets the node, call it n, with the lowest f(n) value from the OPEN list (in other words, the node that we think is the most likely to contain the optimal solution). If n is the goal node, then we are done, and all that’s left to do is return the solution by backtracking from n. Otherwise, we remove n from the OPEN list and add it to the CLOSED list. Next, we generate all the possible successor nodes of n.
For each successor node n, if it is already in the CLOSED list and the copy there has an equal or lower f estimate, then we can safely discard the newly generated n and move on (we can do this since a copy with a better estimate on the CLOSED list means we are already looked at it, and the new copy won’t do any better). Similarly, if n is already in the OPEN list and the copy there has an equal or lower f estimate, we can discard the newly generated n and move on (we are going to be looking at a better version of n later, so no need to keep this one around).
f no better version of n exists on either the CLOSED or OPEN lists, we remove the inferior copies from the two lists and set n as the parent of n’. We also have to calculate the cost estimates for n as follows: set g(n’) to g(n) plus the cost of getting from n to n’; set h(n’) to the heuristic estimate of getting from n’ to the goal node; and set f(n’) to g(n’) plus h(n’). Lastly, add n’ to the OPEN list and return to the beginning of the main loop.
Pseudo-code for A Star Search :
Initialize OPEN list
Initialize CLOSED list
Create goal node; call it node_goal
Create start node; call it node_start
Add node_start to the OPEN list
while the OPEN list is not empty
{
Get node n off the OPEN list with the lowest f(n)
Add n to the CLOSED list
if n is the same as node_goal we have found the solution; return Solution(n)
Generate each successor node n’ of n
for each successor node n’ of n
{
Set the parent of n’ to n
Set h(n’) to be the heuristically estimate distance to node_goal
Set g(n’) to be g(n) plus the cost to get to n’ from n
Set f(n’) to be g(n’) plus h(n’)
if n’ is on the OPEN list and the existing one is as good or better then discard n’ and continue
if n’ is on the CLOSED list and the existing one is as good or better then discard n’ and continue
Remove occurrences of n’ from OPEN and CLOSED
n’ to the OPEN list
}
}
return failure (if we reach this point we have searched all reachable nodes and still haven’t found the solution, therefore one doesn’t exist)
Pictorial working model
Our task is to find the low cost path from source A to sink or destination F in the given graph
the graph is
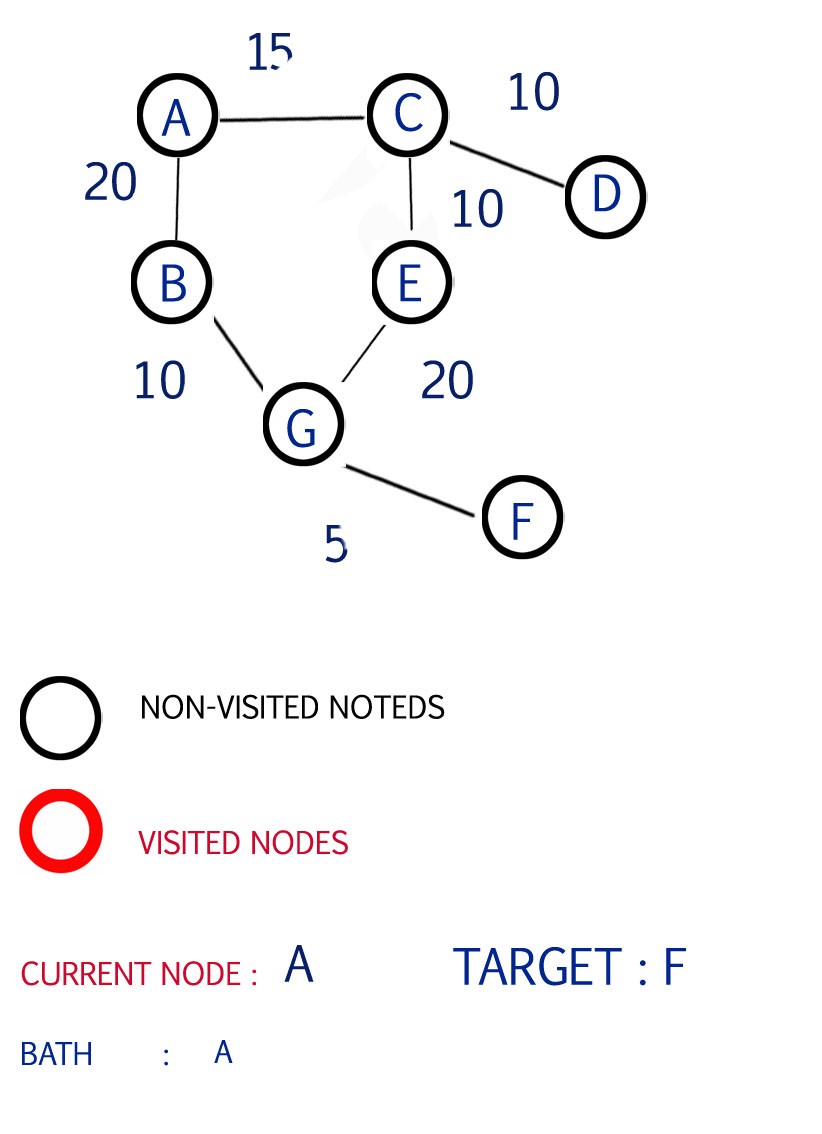
graph
The main idea of the A Star Search ing strategy is to
- Convert the graph into tree
- First visit the lowest cost path among the path available
- Always follow the order to expand the tree
- If the target is achieved stop the search
Step 1
Now we are at the source A so we have to expand the path available with A
path available B,C
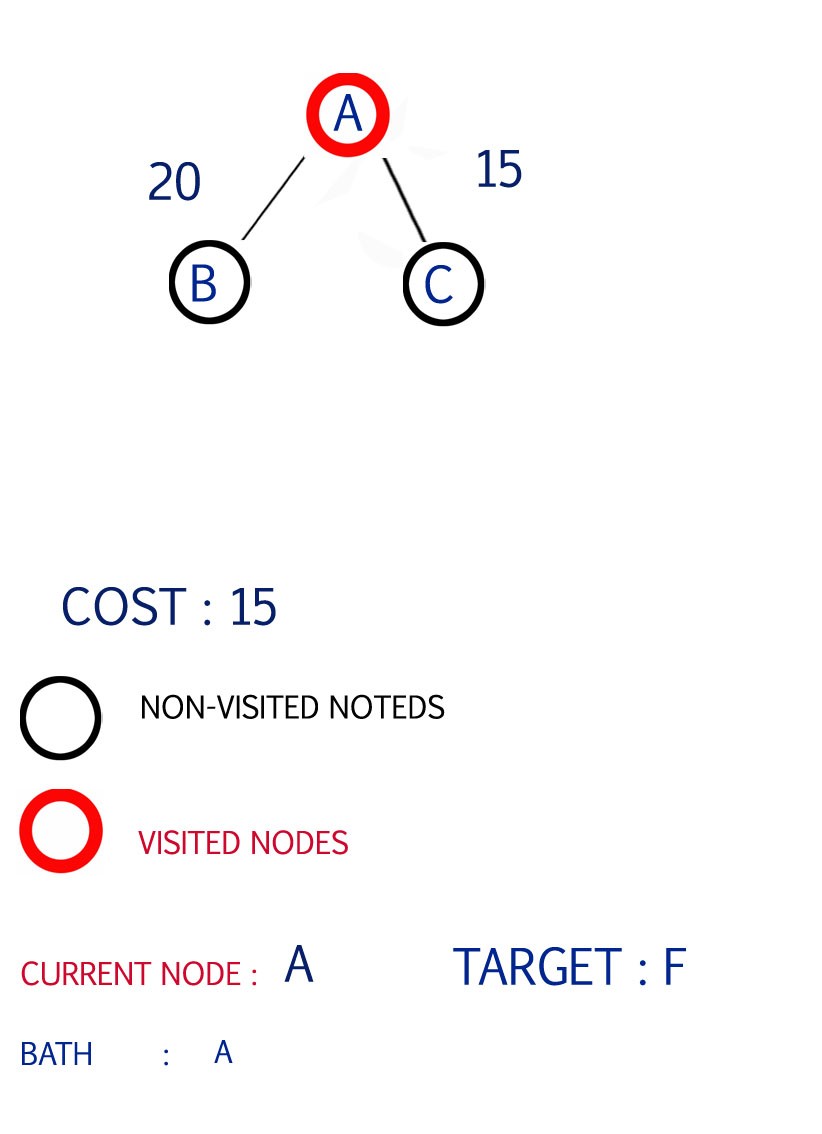
step1
Step 2
Now the shortest path from A is to C
so select C and expand the path from C
Path available E and D
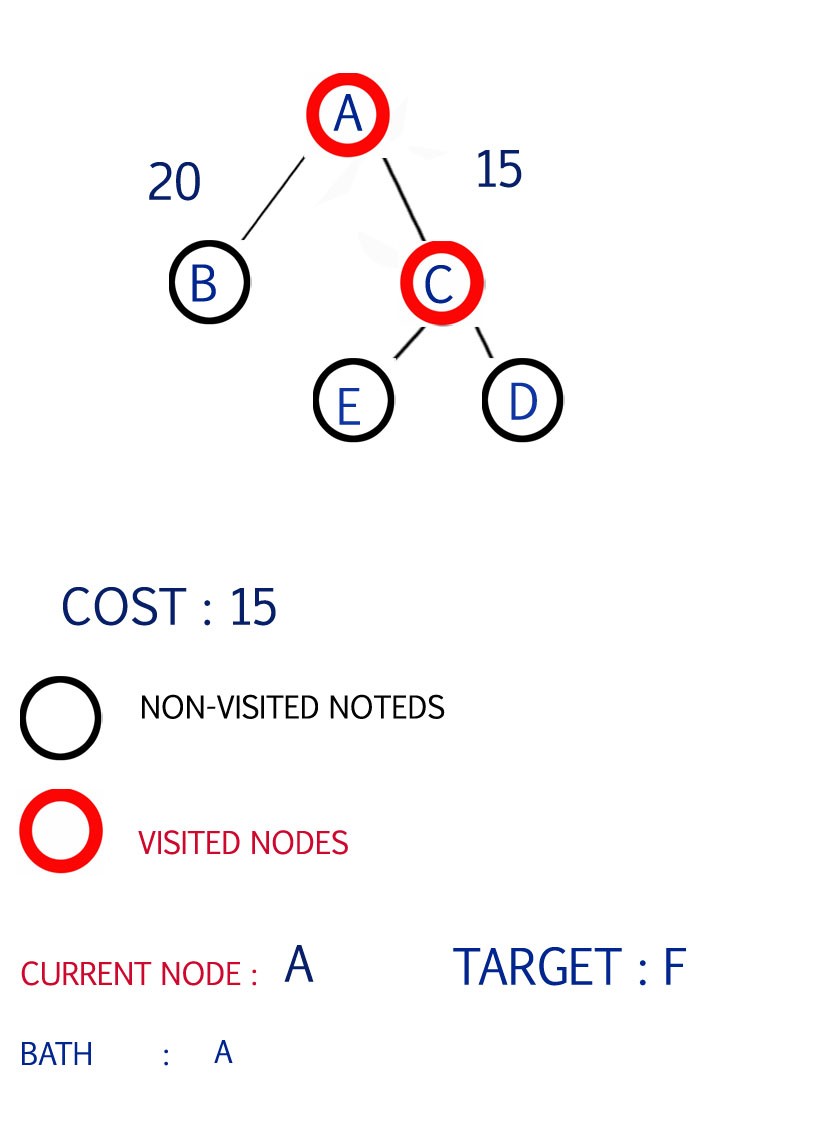
Step 2
Step 3
Now the shortest path from C is to E
so select E and expand the path from E
Path available G
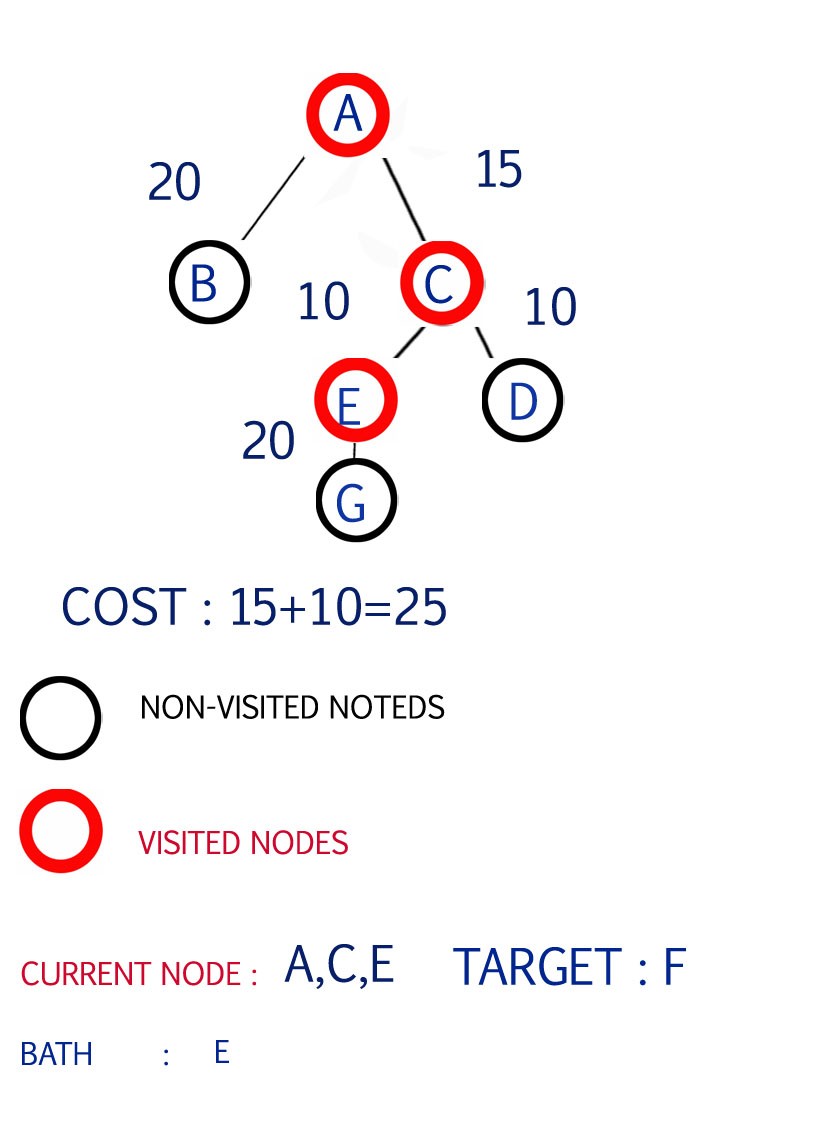
Step 3
Step 4
Now the shortest path from E is to G
so select G and expand the path from G
Path available F
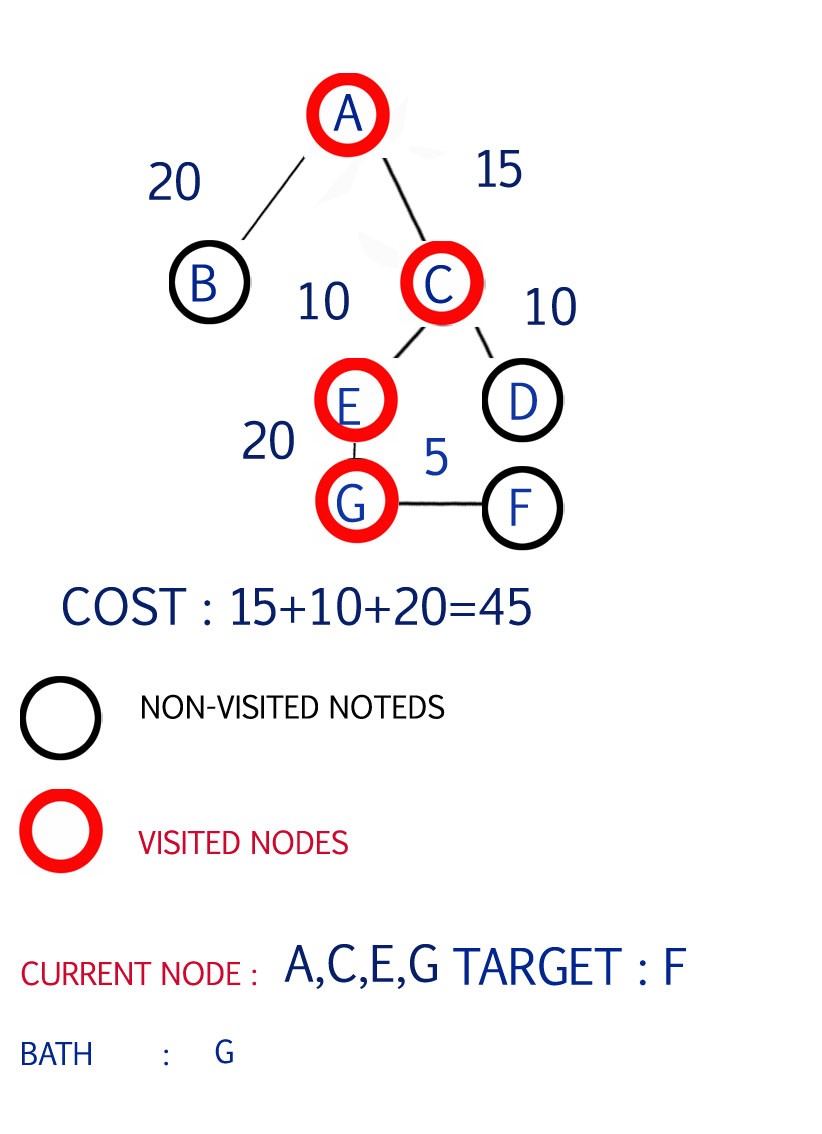
Step 5
Step 5
Now the shortest path from G is to F
F is the target and we have achieved it
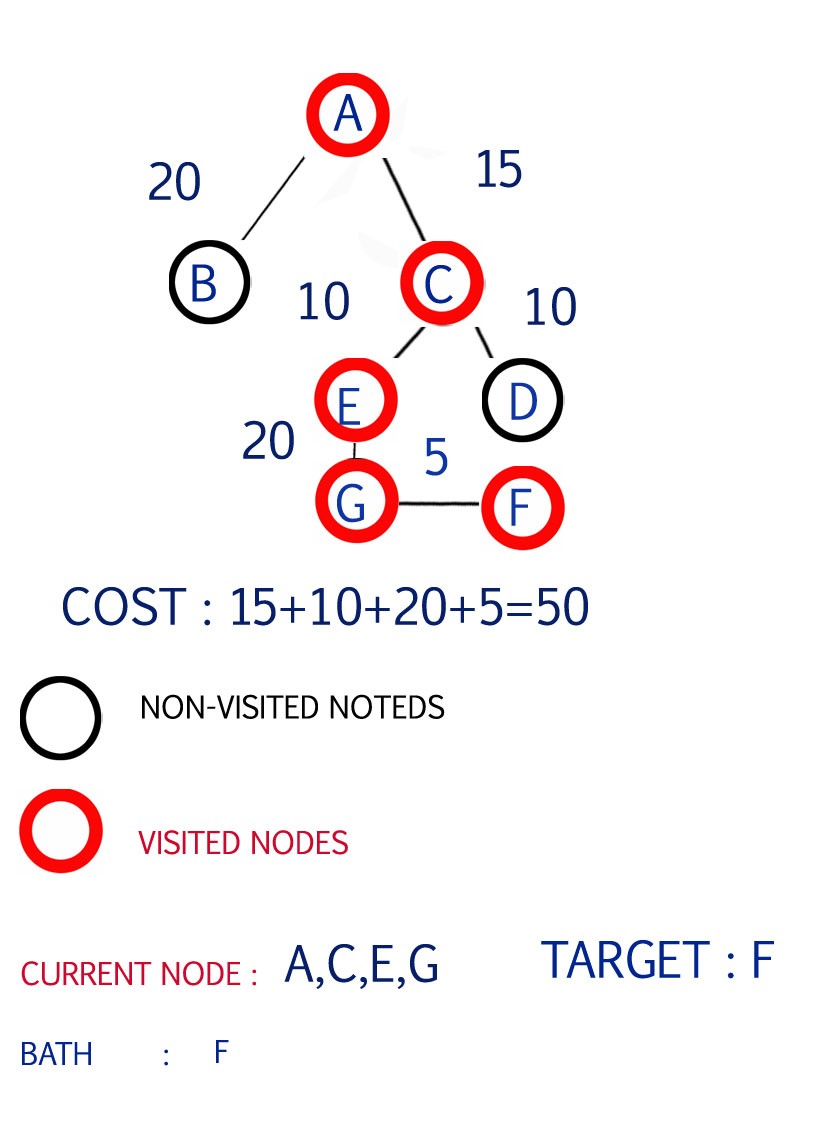
step 6
thus we have achieved the TARGET with the cost of 50
But we cant be sure that this is the lowest cost path.
Possible questions
1)Is A* is optimal
Ans: NO , because the it follows the order of taking the shortest path, if any path is found it assumes that the path is found, but there are lots of possibilities to have other path with low cost then this
2)What can be done to make it optimistic
Ans:By finding the Admissible heuristic h(n)
if h(n) is admissible then it is optimal
3)State repeat state problem
Ans:there is no restriction to plot that any node can be visited only once there are lot of possibility to create tree from a graph, so the node will be repeat in different branches in the same tree
Foe more Searching techniques
Discover more from Our Education | Best Coaching Institutes Colleges Rank
Subscribe to get the latest posts sent to your email.
« PROPERTIES AND USES OF NYLON 66 PROPERTIES AND USES OF POLY ACRYLONITRILE »
Tell us Your Queries, Suggestions and Feedback